Task: Determine which process is allowed to run
1. OBJECTIVES
- Maximize
- CPU utilization
- Throughput (tasks per unit of time)
- Turnaround time (submission-to-completion)
- Waiting time (sum of times spend in ready queue)
- Response time (production of first response)
- Every task should be handled eventually (no starvation)
- Tasks with similar characteristics should be treated equally
2. SCHEDULING QUEUES
- All processes are stored in the job queue.
- Processes in the Ready state are placed in the ready queue.
- Processes waiting for a device to become available or to deliver data are placed in device queues. There is generally a separate device queue for each device.
- Other queues may also be created and used as needed.
 |
| Figure 1. Diagram of process state |
 |
| Figure 2. The ready queue and various I/O device queues |
3. SCHEDULERS
- Purposes: Processes are submitted which will be spooled to a mass-storage device (typically a disk). Select processes from this pool and load them into memory for execution, manage the number of processes in memory (long-term scheduler) and if processes are ready to execute and allocate the CPU to one of them (short-term scheduler).
- Classification:
- A long-term scheduler is typical of a batch system or a very heavily loaded system. It runs infrequently, (such as when one process ends selecting one more to be loaded in from disk in its place), and can afford to take the time to implement intelligent and advanced scheduling algorithms. It is performed whenever a process is created.
- The short-term scheduler, or CPU Scheduler, runs very frequently, on the order of 100 milliseconds, and must very quickly swap one process out of the CPU and swap in another one. It is invoked whenever an event occurs (clock interrupt, IO interrupt, system call, signal,…)
NOTICE- OSs like UNIX, Microsoft don’t use long-term scheduler. Long Term Scheduling is needed for systems that indeed run long term. Those are not long term running machines. You use it for some time and then shut it (or leave it idle). Even if you leave your machine turned on for months at a time, your jobs are still not the kind that require RAM at its disposal to not need long term scheduling. They usually end in a short term. Further, even if you are one of those who start a program and never bother to close it, your machine usually has enough RAM at its disposal to not need long term scheduling. - Swapping programs in and out of memory is the job of mid-term scheduler. With GBs at OS's disposal, the need for interactivity and the programs which usually don't add up to the entire RAM, long term scheduling is not needed for the kind of programs that are run on a desktop.
- Some systems also employ a medium-term scheduler. When system loads get high, this scheduler will swap one or more processes out of the ready queue system for a few seconds, in order to allow smaller faster jobs to finish up quickly and clear the system.
- An efficient scheduling system will select a good process mix of CPU-bound processes (generates I/O requests infrequently, using more of its time doing computations) and I/O bound processes (spend more of its time doing I/O than it spends doing computations).
 |
| Figure 3. Queueing-diagram representation of process scheduling |
 |
| Figure 4. Addition of medium-term scheduling to the queueing diagram |
4. CONTEXT SWITCH
- Whenever an interrupt arrives, the CPU must do a state-save of the currently running process, then switch into kernel mode to handle the interrupt, and then do a state-restore of the interrupted process.
- Similarly, a context switch occurs when the time slice for one process has expired and a new process is to be loaded from the ready queue. This will be instigated by a timer interrupt, which will then cause the current process's state to be saved and the new process's state to be restored.
- Saving and restoring states involves saving and restoring all of the registers and program counter(s), as well as the process control blocks described above.
- Context switching happens VERY frequently, and the overhead of doing the switching is just lost CPU time, so context switches (state saves & restores) need to be as fast as possible. Some hardware has special provisions for speeding this up, such as a single machine instruction for saving or restoring all registers at once.
- Some Sun hardware actually has multiple sets of registers, so the context switching can be speeded up by merely switching which set of registers are currently in use. Obviously there is a limit as to how many processes can be switched between in this manner, making it attractive to implement the medium-term scheduler to swap some processes out.
5. SCHEDULING ALGORITHMS
- Scheduling algorithms or scheduling policies are mainly used for short-term scheduling. The main objective of short-term scheduling is to allocate processor time in such a way as to optimize one or more aspects of system behavior.
- For these scheduling algorithms assume only a single processor is present. Scheduling algorithms decide which of the processes in the ready queue is to be allocated to the CPU is basis on the type of scheduling policy and whether that policy is either preemptive or non-preemptive. For scheduling arrival time and service time are also will play a role.
- List of scheduling algorithms are as follows:
- First-come, first-served scheduling (FCFS) algorithm (first in first out)
- Shortest Job First Scheduling (SJF) algorithm (The process with the shortest expected processing time is selected for execution, among the available processes in the ready queue)
- Shortest Remaining time (SRT) algorithm (A preemptive SJF algorithm will preempt the currently executing process if the next CPU burst of newly arrived process may be shorter than what is left to the currently executing process).
- Non-preemptive priority Scheduling algorithm (the CPU is allocated to the process with the highest priority after completing the present running process).
- Preemptive priority Scheduling algorithm.
- Round-Robin Scheduling algorithm.
- Highest Response Ratio Next (HRRN) algorithm.
- Multilevel Feedback Queue Scheduling algorithm.
- Multilevel Queue Scheduling algorithm.
For instance, you can find some sample codes in here, we will use FCFS and Priority Scheduling algorithms as examples.
1
2
3
4
5
6
7
| typedef struct process { int pid; /* Process ID */ int priority; /* Priority */ int arrival_time /* Time when process submit request */; int burst_time; /* CPU burst Time, duration which processor need to implement a process */ struct process *next;} Process; |
1
2
3
4
| void fcfs (Process *proc);Process *init_process (int pid, int burst, int priority);void list_process (Process *proc);void priority (struct process *proc); |
- We have 4 processes:
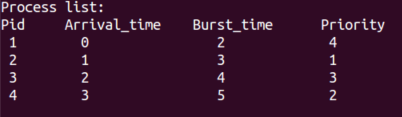
- FCFS algorithm:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| void fcfs (Process *proc) { int start, duration = 0, end, turnaround_time, waiting_time, service_time = 0; Process *ptmp = proc; printf("\n\nFirst come First served scheduling algorithm\n"); printf("Pid\tArrival_time\tBurst_time\tService_time\tTurnaround_time\tWaiting_time\tPriority\n"); while (ptmp != NULL) { service_time = (service_time > ptmp -> arrival_time) ? service_time : ptmp -> arrival_time; turnaround_time = service_time + ptmp -> burst_time; waiting_time = service_time - ptmp -> arrival_time; printf("%2d\t%6d\t%12d\t%12d\t%12d\t%12d\t%14d\n", ptmp -> pid, ptmp -> arrival_time, ptmp -> burst_time, service_time, turnaround_time, waiting_time, ptmp -> priority ); service_time += ptmp -> burst_time; ptmp = ptmp -> next; } printf("END:\tFCFS scheduling simulation\n\n");} |
- service_time is when process is started implementing.
- turnaround_time is the instant that process is completed.
- waiting_time is the duration from submission time to the instant in which process is served. Process comes earlier which will be served before others.
- Priority scheduling algorithm:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| void priority (struct process *proc) { int highest, turnaround_time, waiting_time, service_time = 0; struct process *copy, *tmpsrc, *tmp, *beforehighest; printf("\n\nPriority scheduling simulation\n"); printf("Pid\tArrival_time\tBurst_time\tService_time\tTurnaround_time\tWaiting_time\tPriority\n"); /* Duplicate process list */ tmpsrc = proc; copy = tmp = NULL; while (tmpsrc != NULL) { if (copy == NULL) { copy = init_process(tmpsrc->pid, tmpsrc->burst_time, tmpsrc -> arrival_time, tmpsrc->priority); tmp = copy; } else { tmp->next = init_process(tmpsrc->pid, tmpsrc->burst_time, tmpsrc -> arrival_time, tmpsrc->priority); tmp = tmp->next; } tmpsrc = tmpsrc->next; }; /* Main routine */ while (copy != NULL) { /* Find the next job */ beforehighest = NULL; highest = copy->priority; tmp = copy->next; tmpsrc = copy; /* Find the process with highest priority, but remember the previous process (in queue) */ while (tmp != NULL) { if (tmp->priority < highest) { highest = tmp->priority; beforehighest = tmpsrc; } tmpsrc = tmp; tmp = tmp->next; } /* Process job and remove from copy of process list */ if (beforehighest == NULL) { /* Handle first job (in queue) is highest priority case */ service_time = (service_time > copy -> arrival_time) ? service_time : copy -> arrival_time; turnaround_time = service_time + copy -> burst_time; waiting_time = service_time - copy -> arrival_time; printf("%2d\t%6d\t%12d\t%12d\t%12d\t%12d\t%14d\n", copy -> pid, copy -> arrival_time, copy -> burst_time, service_time, turnaround_time, waiting_time, copy -> priority ); service_time += copy -> burst_time; tmpsrc = copy->next; free(copy); copy = tmpsrc; } else { /* Handle first job is not highest priority case */ /* Point to the highest priority process */ tmp = beforehighest->next; service_time = (service_time > tmp -> arrival_time) ? service_time : tmp -> arrival_time; turnaround_time = service_time + tmp -> burst_time; waiting_time = service_time - tmp -> arrival_time; printf("%2d\t%6d\t%12d\t%12d\t%12d\t%12d\t%14d\n", tmp -> pid, tmp -> arrival_time, tmp -> burst_time, service_time, turnaround_time, waiting_time, tmp -> priority ); service_time += tmp -> burst_time; beforehighest->next = tmp->next; free(tmp); } } printf("END:\tPriority scheduling simulation\n\n");} |
Compile this code with:
cc -o ScheduleProcess ScheduleProcess.c
If you execute file named ScheduleProcess, you will receive this result:
 |
| Received result after executing |
Không có nhận xét nào:
Đăng nhận xét